Effective IAM for AWS
Create IAM principals and provision access
Create IAM principals and provision access
With your AWS account foundation established, it is time to create principals that will use those accounts and provision access to necessary resources.
If you've set up network access controls for a traditional datacenter, this job will probably look significantly different. IAM principals and policies are first-class resources. They are tightly integrated into the compute platform and AWS service authorization. IAM security policies control whether a principal can execute AWS service API actions. IAM principals are even usable in many AWS network access controls. Finally, AWS records IAM principal actions in CloudTrail audit logs.
In this chapter you'll learn how to model principals for people and applications, then provision access policies that match their use cases. Finally, we will establish a control loop that secures access over time.
Getting started
An AWS account’s root user is too powerful for everyday use. Logging in with the root user should be done rarely, usually for ‘break glass’ scenarios to deal with major problems. After securing the root user, you should control access to it tightly, monitor its activity using CloudTrail, and consider restricting root's capabilities using Service Control Policies. Each account's root user is automatically identified in IAM with an ARN that looks like: arn:aws:iam::12345678910:root.
You will need the root user for one important task. Create an IAM user with administrative privileges to bootstrap the account, unless you already created a privileged IAM principal. Now you can create IAM roles for both people and applications, then grant access to the AWS services and data resources they need.
All AWS compute services support running workloads as an IAM role. And you can connect people's existing corporate identities to IAM roles.
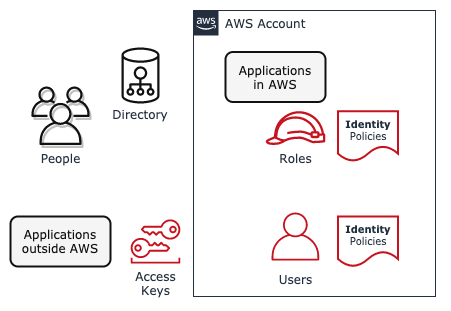
Figure 4.1 Create IAM Principals for People and Applications
EC2 compute instances, container tasks, and Lambda functions can all retrieve an identity document with short term credentials from the compute service's built-in metadata endpoint. Applications use these credentials to authenticate as the assigned workload's IAM role to AWS services such as S3. The AWS SDKs, AWS cli, and applications built for AWS use these credentials automatically as part of the standard AWS credential chain.
Generally, IAM users should only be used by applications running outside of AWS. Avoid granting permissions to IAM users directly. Instead grant access to roles and enable users to assume roles they need.
Using roles this way enables least privilege access control and only grants temporary credentials. Additionally, federated access only works with roles.
But what roles should we create?
Roles for people
First we'll need roles for people. These roles should map to a job function or job to be done.
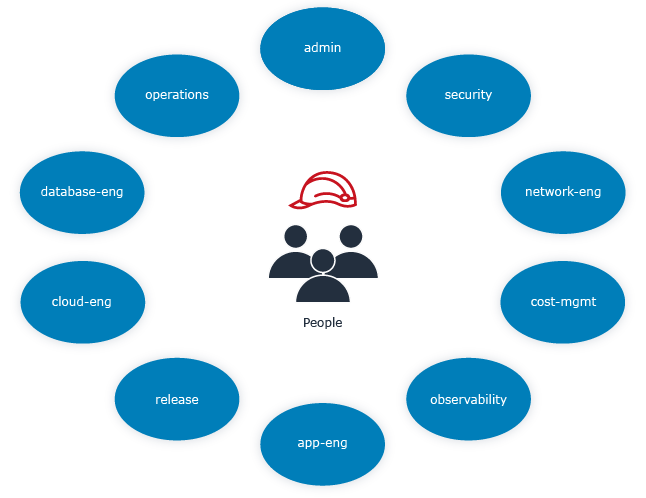
Figure 4.2 IAM roles for people
Define a common set of logical roles for people and deploy them into your AWS accounts. You will probably need a set of roles like:
- admin
- security
- operations
- network-eng
- database-eng
- cloud-eng
- release
- observability
- app-eng
- cost-mgmt
See Appendix - IAM Role Quickstart for these roles' responsibilities and which Enterprise and Runtime accounts they have access to.
When a person or group does multiple jobs, give them access to multiple roles. This helps you implement least privilege and avoid every role's permissions converging to administrator.
There are a few important things to note about these standard people roles.
First, these roles will generally exist in each account, but often have different privileges appropriate for the phase of delivery. Many roles will have more abilities in development than production. For example, application engineers may have the ability to create and delete databases in dev, but not in prod.
Second, people in different departments or business units will use the same logical role, but only in the AWS accounts for their business unit. For example, a Cloud Engineer in the Personal Banking department will only have access to the cloud-eng role in the Personal Banking department's AWS accounts, not the Data Warehouse's accounts. The converse is true of the Data Warehouse's Cloud engineering team; they do not have access to Personal Banking, even though they use the same logical cloud-eng role.
How do we link people to the right roles in our accounts? By federating corporate identities.
Federate identity for human users
Organizations must enable people to access AWS securely. You could do this by creating IAM users and access keys for everyone. But that would create a huge secret management problem and access to the web console is inconvenient. Besides, people already have trusted identities managed by their organization's corporate directory (Microsoft ActiveDirectory, Google Workspace). Instead of creating IAM users, organizations should federate access from their existing directory to AWS roles.
Organizations federate identity by linking a person's identity in the central authoritative corporate directory to other identity management systems. Federation allows people to move quickly and securely between systems — without managing another password.
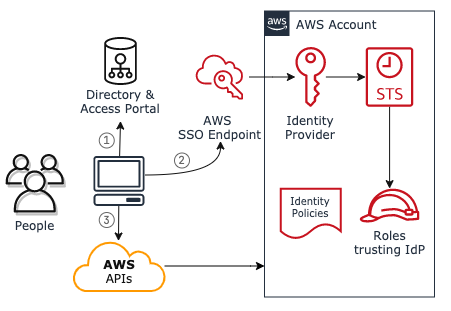
Figure 4.3 Integrate corporate identities to IAM roles using an Identity Provider
Connect your organization's existing people identities to AWS IAM roles in an account with an identity provider (IdP) using SAML or SCIM. The AWS account will now trust the IdP to authenticate users. Access administrators map users or groups in the corporate directory to IAM roles in AWS using the IdP. People access AWS by signing into the identity provider's access portal with their username or email address, then selecting the AWS account and IAM role they want to use.
People now have access to AWS without managing a new password or AWS access key, which would be required when using IAM users to access AWS accounts.
When integrating AWS with your identity provider, design high-integrity change workflows.
First, define a repeatable process for provisioning access for a new IAM role in the IdP. Consider defining:
- the allowed access as data in the corporate directory
- a mapping of authoritative directory groups to IAM roles in a table or other easily reviewable data structure
Second, you need a robust change process for adding and removing people from the groups that allow access to IAM roles, particularly privileged ones. Review and approve requests for access to IAM roles per organization security policy. People might initiate their request for privileged IAM roles in production by contacting the IT helpdesk. But adding a person to a privileged group should require approval from managers of that AWS account.
Roles for applications
IAM roles for applications differ significantly from people. The specific set of application roles an organization needs for its application workloads are highly dependent on those workloads. But those workloads will fall into a few categories:
- End-user Applications
- Orchestration
- Security and Governance
- Observability
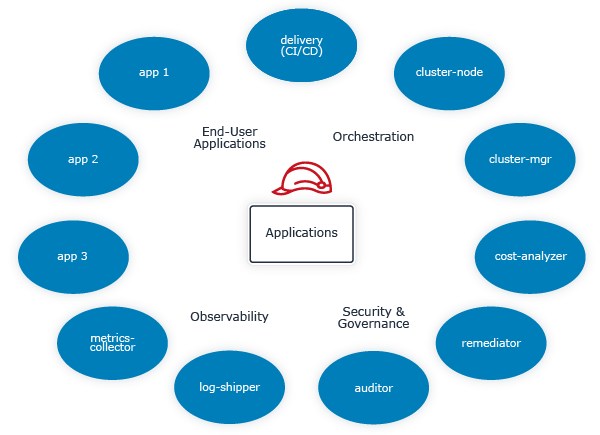
Figure 4.4 IAM roles for applications
Think of the compute instance running an application as a generic process container. In order to execute the process inside that compute container successfully, one or more programs may need to access an AWS service. The programs may need to do any of:
- load configuration from SSM Parameter Store
- read or write objects in S3
- store items in DynamoDB
- read or change AWS compute, data, or security resource configurations
- read CloudWatch metrics or logs
Almost every interaction with an AWS service requires permission to be granted using IAM. There are very few application deployments that don't need any IAM permissions. Even a web server deployment on EC2 serving a static website will likely need to ship its logs to S3.
Applications are programmed to accomplish specific tasks and so will require specific IAM permissions to operate correctly. These permissions generally do not vary by software delivery phase because the application's programming does not change. Only the environment the application runs in and the data it processes changes by delivery phase. And while many applications are similar to each other, it's uncommon for two applications to need exactly the same permissions, and almost never to the same data sources. This is true even for applications following the organization's standard architecture(s).
So create an IAM role for each application and phase of delivery. This includes both your applications and third-party applications running in AWS. Develop the application's Identity policy and any relevant Resource Policies with the application. IAM policies control whether the application will function correctly, so it's critical to develop, test and promote the application's IAM policies along with the rest of the application code. Ideally, IAM policies should be managed within the application's source repository and delivered with the application's delivery pipeline.
This approach automatically synchronizes security policy changes with the application, and avoids coordinating security policy updates via email or chat.
The applications serving end customers are not the only applications running in AWS. There are also automation applications that deploy, orchestrate, and support operations. These automation applications should also have their own distinct roles and appropriate identity policies.
Automation services often need access to powerful AWS control plane APIs or many data sources. Regular applications should never run with an automation application's principal.
Many people accidentally run containerized application services as the container cluster's EC2 instance orchestrator role. This mistake is easy to make with Elastic Container Service (ECS) because of that service's task defaults. However, running applications as the orchestrator:
- gives all applications the ability to operate with the elevated privileges of the orchestrator, which usually has the ability to provision compute and access secrets
- eliminates isolation between applications running on the cluster, enabling easy horizontal pivots between applications by an attacker
This example illustrates why it's so important to run applications with dedicated IAM roles. You'll need many IAM roles to model your applications, often more than 100 in each account. Fortunately, there is no direct cost for IAM resources. The real costs come from managing their access.
Now that we've provisioned AWS access to people and apps, we need to ensure those principals have only the access they need. Forever.
Secure access over time
Many organizations spend a lot of energy, time, and money implementing and monitoring access controls with little to show for it. Those organizations may have deployed several security tools and stored a lot of data in a SIEM. But they still have weak security policies and wait a long time for them.
Why is that?
Previously, we established that AWS security policies are hard to get right and difficult to validate. Those are important factors, but not the whole story.
Suppose an organization has information confidentiality requirements such as:
- Must preserve privacy of users’ data
- Must preserve confidentiality of organization’s intellectual property
These requirements might be collected into a ‘least privilege access’ goal for the organization’s applications or at least applications with ‘critical’ data.
But no tool can directly tell you if you’ve implemented “least privilege” access correctly, let alone do it for you. That tool won’t have all the necessary information to make and implement a decision.
No tool will.
Implementing and verifying least privilege access requires information spread across many people and tools. When security policy engineering processes are not well-defined or optimized, security specialists spend more time collecting and synthesizing data than analyzing and improving security policies. And people who are not AWS security experts cannot help.
Let’s fix that!
⚠️ Warning: We are not going to invent anything new here.
We will create a general process control loop to define, implement, and verify access controls function as intended using established best practices from Process and Safety Engineering.
So you can secure access now, and in the future, as the world changes.
Figure 4.5 Secure access over time
Start with the high level needs of the information security control process. You need to:
- implement initial access controls
- update access controls as the application and business changes over time
You can do this with a process control loop that continuously converges security policies to intended access.
A real-world AWS application access control loop
Consider a credit-processor application that stores its data in S3. The application is the process and we want to control that process' behavior.

Figure 4.6 Process behavior to control
Process controllers maintain process output or operating conditions by modeling process operation, measuring process inputs and outputs, and adjusting inputs to ensure the process operates within the desired range.
Process control is pervasive:
- Thermostats control climate in buildings
- Electrical utilities monitor load and generate electricity to match
- Agile teams gather product feedback and prioritize the most important work
You can also use feedback process control to ensure information security requirements are met.
This diagram illustrates securing access to an application’s data with a simple control process that integrates feedback:
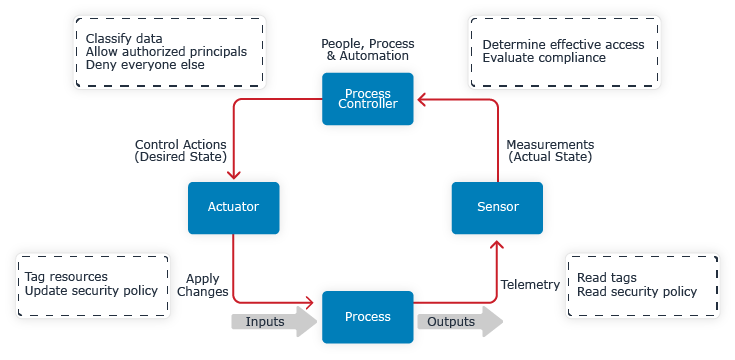
Figure 4.7 Secure data using process control with feedback
Every control process needs a process controller, actuator, and sensor. When a component is missing, faulty, or overloaded, the process will not be controlled effectively. The process may function properly and it may pass an audit (heh), but it won't be because the controls had anything to do with it.
Organizations often have elements of a control process, particularly ‘sensor’ tools that gather raw telemetry. But maybe:
- Measurements are not converted into understandable, actionable information
- People reviewing measurements don't have sufficient context to decide whether the configuration is correct
- People are overloaded by the volume of measurements
- Security controls are not updated based on the collected information
Let’s examine each component’s responsibilities and trace information through the control loop. As we step through each component in the process, think about whether:
- Your access control process has an implementation of each logical component
- Components are automated or manual
- Information flows between each component
- The process control loop completes in your team or organization
How long does it take to go around the loop in practice? A day, a week, a month, or more?
Process Controller
The first process control component is the controller. Suppose the organization implements the “least privilege access for confidential data” constraint by ensuring between 1 and 5 authorized principals have access to Confidential application data. That general constraint provides room for the application, backup processes, and Tier-3 customer service to have access to that data. That constraint would be violated if all applications had access to the sensitive application data, a common problem.
Guided by clear requirements for implementing least privilege, we can automate the policy implementation. Use infrastructure management tools like Terraform or CloudFormation to automatically:
- Classify data and compute resources
- Specify who is allowed access to the data
- Deny everyone else access
Enable engineers to make good access management decisions by adopting libraries with usable interfaces that encapsulate expert AWS security knowledge. Provide engineers with a way to specify who should have access with the information they already have: IAM principal ARNs and high level access capabilities. Use a standardized set of high level access capabilities to keep your team out of the weeds of AWS IAM and API actions. This greatly simplifies both implementing and reviewing security policy changes.
If the application’s data is stored in an S3 bucket you could implement that with k9 Security Terraform module for S3:
module "s3_bucket" { source = "k9securityio/s3-bucket/aws"
logical_name = "credit-applications" logging_target_bucket = "secureorg-logs-bucket"
org = "secureorg" owner = "credit-team" env = "prod" app = "credit-processor"
confidentiality = "Confidential"
allow_administer_resource_arns = [ "arn:aws:iam::111:user/ci", "arn:aws:iam::111:role/admin" ] allow_read_data_arns = [ "arn:aws:iam::111:role/credit-processor", "arn:aws:iam::111:role/cust-service" ] allow_write_data_arns = ["arn:aws:iam::111:role/credit-processor"]}This code describes the desired state of the credit processor application’s data resources and security policies.
Engineers declare access to data in the bucket with words like administer_resource, read_data, and write_data. Changes to these simplified access capabilities are easy to implement and review. Reviewing the ~200 line bucket policy generated by the library much less so. In a code review, engineers and tools can see the data is tagged Confidential and 4 principals are allowed to access it. So the least privilege access constraint is met and our business objective achieved.
Codifying security best practice into libraries makes those practices accessible to every team and engineer.
Once the team has decided on the desired access to grant, the actuator component implements any needed changes.
Actuator
The process controller communicates the desired state of the system to an actuator. The actuator is an infrastructure management tool that knows how to examine the running system and converge it to our desired state by:
- Computing changes required to converge reality to desired state
- Applying changes to security policies and resource tags
Infrastructure management tools split computing and applying changes into two steps. This enables engineers to verify the changes are safe and will do what is desired.
Engineers can review the change plan to double-check the least privilege access constraint is met prior to applying.
Once reviewed and approved, engineers apply changes using the infrastructure management tool.
At this point several things can and do happen.
The infrastructure management tool may apply the desired changes successfully. Or it may fail, sometimes partially. Even if a change application succeeds, another actor may reconfigure the system manually in response to a production incident or to test something. A competing control plane may overwrite changes. The world is a complex place.
So while we have described how access should be configured and used a tool to implement that in the running system, we need to verify reality matches our desired state.
Sensor
Sensors gather data from the running system so that engineers can analyze its actual state. Actual systems change for many reasons, both planned and unplanned, modeled and unmodeled. We need sensors to collect data from the running system continuously so the control loop can verify constraints are met.
To analyze access control, sensors may read low level telemetry like:
- The actual security policies
- The actual tags on the resource
- A log of what access has been used recently
- A system probe's report of whether access is allowed
- Differences between actual and desired state defined by infrastructure code
The sensor can transmit this raw telemetry directly to the process controller for evaluation. For the credit-processor application the sensor could report the actual policies and tags. But then the process controller needs to compute access itself. As of mid-2021, there are no native AWS tools that sense and report what access IAM principals in an account have to an S3 bucket. The closest options are:
- AWS Access Analyzer which will generate findings for buckets that are externally accessible
- AWS Access Analyzer last used service will tell you which S3 actions an IAM principal last used
- CloudTrail logs when a principal accessed a bucket via a control API or data API (optional)
Alternatively, a sensor may compute higher level measurements that are easier to understand and send that to the process controller.
An example of a higher level measurement is the effective access IAM principals have to data and API actions. Here’s how k9 Security reports the effective access to the credit applications bucket:
| Service Name | Resource ARN | Access Capability | Principal Name | Principal Type |
|---|---|---|---|---|
| S3 | arn:aws:s3:::secureorg-credit-applications | administer-resource | admin | IAMRole |
| S3 | arn:aws:s3:::secureorg-credit-applications | administer-resource | ci | IAMUser |
| S3 | arn:aws:s3:::secureorg-credit-applications | read-data | credit-processor | IAMRole |
| S3 | arn:aws:s3:::secureorg-credit-applications | read-data | cust-service | IAMRole |
| S3 | arn:aws:s3:::secureorg-credit-applications | write-data | credit-processor | IAMRole |
Table 4.1: Example of high level measurement of effective access to an S3 bucket
These measurements are intended for direct consumption by a process controller. The report clearly shows:
- the access capabilities that the
admin,ci,cust-service, andcredit-processorprincipals have - that no unexpected users or roles have access
People acting as process controllers find this information much easier to interpret than analyzing policies in their heads, and the result is far more accurate.
Closing the loop
Now let’s close the control loop. The people and tools that implement the process controller receive the sensor’s information and evaluate compliance with the “least privilege access” constraint. Then the controller decides if additional control actions are needed.
If the constraint is violated it could be that too many principals were given access, the data source supports multiple use cases, or another issue.
To secure access over time, you'll need to execute the control loop frequently enough to keep pace with changes in the environment and security objectives.
Organizations should adopt standardized models, processes, and self-service tools that help all teams implement common constraints like least privilege access. This includes:
- Classifying data sources according to a standard so everyone has the context they need with, e.g. a tagging guide and infrastructure code support for that tagging standard
- Simplifying access capability models for declaration and analysis
- Generating secure policies using infrastructure code libraries within delivery pipelines
- Analyzing effective access principals have to API actions and data
- Notifying teams when the actual state of access does not match the desired state
These tools help teams implement and execute the access control loop easily and autonomously. Teams can declare the access they intend, detect when reality drifts, and address issues themselves using their local context. This improves and scales information security while unburdening security specialists from repetitive work.
Summary
Create IAM roles for people and applications. Avoid IAM users and credential management where possible. Run applications using IAM roles with least privilege Identity & Resource policies, ideally defined and delivered by the application's automated delivery process. Connect people to IAM roles for their job function in AWS using their existing corporate identity.
Then secure access over time with a process control loop that repeatably defines, applies, and reviews access policies. Focus on the most important controls. Support people’s decision making with automation so that you can make the most of people's context, attention, and skills. When you provide process controllers digestible and actionable information, the control loop can execute frequently, and your organization can detect and resolve hazard conditions quickly.
Next you'll learn how to simplify access control implementation by packaging the best, highest leverage parts of AWS IAM into secure building blocks.
Edit this page on GitHub