Effective IAM for AWS
Secure AWS IAM continuously
Secure AWS IAM continuously
It is not enough to do your best; you must know what to do, and THEN do your best.
Secure AWS IAM continuously.
That might be the ultimate challenge for AWS customers.
We've covered the knowledge, architecture, and tools to meet this challenge.
But how does it all fit together? Who should do what?
We need a process to operationalize AWS IAM security at scale. That process needs to continuously secure resources and verify they're actually secure. And real engineers need to execute that process with reasonable effort on a useful frequency.
A few clear-cut hours each week, not arbitrary fire drills.
In this chapter, we'll secure AWS continuously by synthesizing the concepts we've learned into an effective and scalable control loop. We'll highlight the key integration and performance requirements of each component so that you can audit and improve IAM access controls frequently. Then we'll discuss how to deploy this process successfully within your organization.
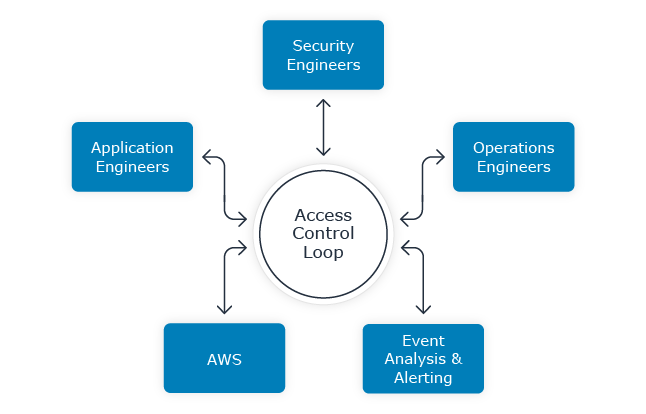
Figure 7.1 Access Control Loop in Context
Skilled people are the most valuable part of any control loop. But there is conflict:
- ultimately, people must decide if access is correct and what changes to make
- they have many other decisions to make and work to do
We need to use people's time and attention wisely. This is particularly true of cloud security engineers, those seemingly mythical unicorns spanning Development, Security, and Operations. So we'll simplify and productize the access control process. Then we'll train and motivate the whole organization to execute it. We'll get to that in a moment.
Start by determining the process capability needed to be effective.
Capability
We want to design our control process so it executes frequently enough that we detect and resolve problems quickly. But we don't want to waste time and money executing a process more frequently than needed.
First, establish a target objective for the control. For example, an organization may want to ensure access to confidential data sources is correct monthly.
Second, develop a realistic understanding of how much energy is required to execute the control loop once. If it takes 4 person-days to execute the loop, you're unlikely to execute it monthly.
Setting frequency requirements and effort budgets allows you to eliminate design alternatives with quick math rather than painful experience.
Let's step through an example. Suppose a Fintech company wants to verify its confidential data access controls work as intended. This company has 10 related applications. The applications are delivered together through three AWS accounts: dev, stage, and prod. Three of the applications manage and should have access to confidential data.
The organization has a 'least privilege' access policy, so the org must:
- verify each application has the access it needs
- verify each application does not have unneeded, excess permissions, particularly to data
- verify internal processes and people do not have excess permissions, particularly to Confidential data
The organization must analyze access for 10 applications plus internal processes, then converge to least privilege each month. By policy this needs to happen in production. Stage is probably in scope since it has an unscrubbed copy of production data. Engineers manage infrastructure with code. They promote security changes with the application from dev to stage then prod. Analyzing access in dev will help application teams get the policies correct.
These applications interact and each application changes independently. It's a complex system. To verify access, the organization should check 30+ configuration sets each month. Or at least the 10+ production configurations.
The key observation is that the organization must be able to execute the access control loop tens of times per month.
The organization is growing and adding a couple new applications per year. So the Security Architect planned for 50 executions per month. That gives the process room to work for the next 2-3 years.
Who actually knows what access should be?
Now let's figure out who knows what the access should be.
Application architects and engineers are generally the people who know who should have access to data. They build the software that interacts with data stores. They know whether collaborating applications use their application APIs or data stores. Of course, sometimes nobody knows and you have to go figure it out.
Use tags to communicate which application owns each data set and its expected confidentiality. Sharing that context enables people and automation to understand the purpose of a particular data store. Now Security and Cloud teams can create governance processes that identify gross irregularities. And they can empower application engineers to validate access.
If an application engineer reads a report describing:
- the effective access of each application IAM role or user
- who can access their application's data sources
Then the engineer might be able to verify access is correct in 5 minutes or less. If they have a list of access changes since the last review, then they might be able to check access in 30 seconds.
But if that same engineer has to go figure out what the expected access is on their own, they will likely spend a couple days (or weeks) working out the effective access, only to produce an inaccurate answer. Wise engineers will recognize the futility of the task and respond "I don't know" ¯\_(ツ)_/¯. Hopefully they say that instead of, "looks good to me."
Application engineers should be able to say what access should be and whether the current access is correct.
Who can change access?
Access changes have a similar story. When an application needs additional access to AWS services or data, application engineers work with cloud and site reliability engineers to provision access. Without usable libraries to generate policies, teams often spend days figuring out what should go into a policy and implementing it.
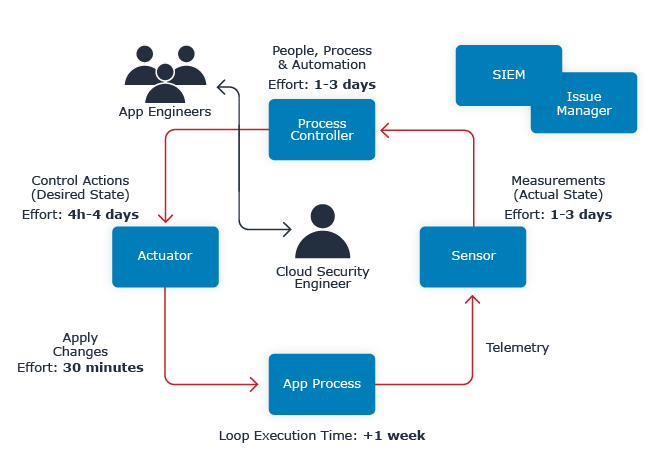
Figure 7.2: Unscalable Access Control Loop
A couple of days here, a meeting there, pretty soon you're talking about real waste.
In the Fintech cloud migration example, custom policy development overloaded the lone cloud security expert. The app team only knew what access the app needed at a high level. The expert implemented custom policies for each app based on the app team's understanding and test deployments. The organization delivered about one newly-secured application per week.
This approach consumed the Cloud team's security expert for a full quarter. Policy development delayed delivery until they decided to ship apps with excess permissions, then fix it after launch. Further, changes are still running through the Cloud security expert. Only the expert really understands the policies.
The organization averages 1-2 changes per week. The Cloud team now reserves 50% of the Cloud security expert's capacity for those events.
Unfortunately, the organization cannot implement periodic access reviews without overloading the expert. They've been trying to hire another expert but that position has been open for 5 months.
Key Result: The organization cannot fulfill its confidential data access review requirement.
Further, there's no capacity buffer to absorb unforeseen events and vacations are a problem. They currently scale cloud security by adding experts, a difficult and expensive approach.
But consider an organization that manages security policies with usable infrastructure code libraries. Application engineers can safely configure access on their own. Cloud and Security Engineers can review access changes during delivery or when requested. Now delivering an access change might consume a few hours of application engineering time and an hour or two of review time. This unblocks delivery and relieves pressure on experts.
Notice a difference in kind emerging:
- Efficient and scalable access control processes have the potential to succeed.
- Inefficient and unscalable processes will not succeed.
Application engineers must be able to change access safely with minimal demands on cloud security experts.
We know what we need to do: enable application engineers to review and change access easily.
That's a big change in many organizations. So let's discuss how to change how you do security.
Change the way you do Security, successfully
Changing the way an organization works is hard. But you can influence the outcome towards success. Use the insights and playbook from Influencer: The New Science of Leading Change1.
Influencers focus and measure the key behaviors that create change. In this case, the behaviors are actually reviewing and improving access control policies so that information security improves. Influencers use multiple sources of influence to reshape behavior in the right direction and increase probability of success by 10x. These influence sources span ability and motivation:
| Ability | Motivation | |
|---|---|---|
| Personal | Help them do what they can't | Help them love what they hate |
| Social | Provide assistance | Provide encouragement |
| Structure | Change their space | Change their economy |
Ability
Increase the organization's ability to execute the control process successfully. Focus effort on improving frontline workers' capacity to manage IAM safely. Provide engineers with robust tools, practice, and support.
Focus on app engineers because: They have the application domain knowledge (context) necessary to secure applications. Enabling app engineers unloads Cloud security specialists. Security changes should integrate with the application's regular delivery process.
Enabling application engineers to manage access may feel unnatural at first. And application engineers may not want new responsibilities
But you must increase the set of people who can manage access safely. And access changes must get on a fast, well-trodden path to production. Only then can you meet the organization's requirements and better security outcomes.
Improve engineers' ability to control access at three levels: Personal, Social, Structural.
Personal: Help them do what they can't
Application and cloud engineers won't write great policies or assess access correctly on their own. You have to help individuals create the outcomes you want in the environment they work in.
Don't just point engineers to the 800+ page AWS IAM user guide and say, "use the best practices" or send them to a half-day workshop on IAM.
Instead, provide engineers with:
- Simplified interfaces to AWS security that help them make good decisions with the knowledge in their head
- Productized components that generate secure policies and report access in language they understand
- Training on how to use the security components and execute the control process
- Safe ways to practice using what they've learned
- Support configuring components and security advice
Increase the ability of individual engineers to build more secure systems. It's the most important factor for improvement program success. If the engineers closest to the problem can't understand and improve access safely, it's likely no one will.
Observe application engineers using the security tools and components you adopt. Notice what people don't understand and where they make mistakes. It's not enough for an engineer to be able to get it right eventually. Improve those tools so they "can't get it wrong" — like professionals.
Provide a safe way for engineers to practice using these tools in a training or test environment. Start by integrating the tools into your reference and training applications. Engineers build knowledge of how to use the tools safely and what "good" looks like through practice. This knowledge and experience is essential for them to operate independently. Then they can try with their own application.
Unload experts by supporting engineers with good documentation, examples, and how-to guides.
Of course there will always be questions in complex domains like security.
Social: Provide assistance
Engineers will have questions, need help, and "permission" to change security controls. Create a place where adopters can ask questions and get good answers, delivered with a smile. 🙂
The environment should encourage engineers to say "I don't know" and ask for help. Otherwise your security issues will remain "undiscovered" and unaddressed.
Consider creating a Security Guild that develops, supports and encourages security practices. The guild can congregate in an open group chat channel. Engineers can get help from people with both formal and informal security responsibilities.
Guilds are a great way to:
- scale the support load
- surface problems with the process, training, and components in an informal way
- identify and document frequently asked questions
- identify topics that need a deeper discussion
- develop & share best practices within your organization
- let people demonstrate the knowledge they've gained and lessons they've learned
Once you've established a guild, lift relevant private conversations into the guild's view. This shows everyone the normal day-to-day experience with the process and opens it to improvement.
Structure: Change their space
If security is going to be every engineer's job, then security should show up where engineers work.
Integrate security into engineers' existing workflows and information sources. Make security capabilities available to engineers on-demand.
Some ways to do this are:
- Let engineers pull routine security work to them through normal product delivery processes. It's less overhead than pushing security work through special projects.
- Provide libraries that generate secure policies for their infrastructure code and delivery process.
- Display access control information in their existing monitoring dashboard.
Don't force each team's engineers to figure out how to integrate security. They either won't integrate it or each team will do it differently.
Scaling Security
Information Security teams have screamed about a 'personnel shortage' for years. And it's only getting worse, "5M+ open positions!" 🙄.
It's time to change the way we secure information.
Don't put security specialists within the control loop. That directs application changes right into one of the organization's tightest bottlenecks. We're blocked! 👿
Security specialists should set up a scalable control loop. Then they can govern its execution with periodic inspections.
If your Enterprise has a Security Operations Center (SOC), the SOC can triage access alerts. Start with Enterprise-wide duties like monitoring IAM admins and access to known critical data stores. To integrate the SOC further into the loop, you must tag data resources with context needed to analyze access and owner contact info (c.f. Cloud Deployment Tagging Guide). The SOC can't look at a list of buckets and 'just know' which ones are important, nor who to contact when they're overly accessible.
These recommendations will enable your development organization to secure access continuously. Now let's motivate them to do it.
Motivation
Enabling people to do the right thing is necessary. But you also need to motivate people to use those abilities. Motivate people at three levels:
- Personal
- Social
- Structural
Personal: Help them love what they hate
Hard work pays off in the future. Laziness pays off now.
Application and Cloud engineers may not like reviewing or improving access right now, particularly repeatedly. You'll need to change that. Interviews with practitioners identify the primary reasons: security policies are difficult to write and nearly impossible to validate without breaking something. That experience is time consuming and painful. So normal people won't do it. Security is deferred until 'later' (like after a breach).
But it's essential to actually complete the loop.
There are several ways to help people love what they currently hate. Let's examine three tactics to motivate individuals to secure access.
First, allow for choice. Recognize that completing this security loop is likely a medium-priority task. Agree upon and clearly communicate the priority of this task throughout your organization. If a team isn't able to complete the task, ask them what led to that and listen. Were they overloaded? Was there a problem with a component? What led to them trading off this security task for something else? Then check if this is happening elsewhere.
Second, create direct experiences that show the risk of excess permissions in a "game day" exercise. Configure a test environment with a copy of a team's application. Give participants a set of actions they can execute to exfiltrate or destroy their application's data. Then let them do it.
Three, make it a game. Implementing least privilege can be extremely challenging and you can use this to your advantage. People like challenges, especially engineers. Use a tool to analyze, then score each principal's access to APIs and data. More points for more access and a multiplier for critical APIs like IAM and data sources. Lowest access scores win, just like golf. Engineers will be shooting for par in no time.
Social: Provide encouragement
No influence is more powerful and accessible than persuasion from those we work with. Ridicule and praise from our peers and organizational leaders can do more to assist or hinder change efforts than any other source. Rolled eyes from a team lead can negate the good work of a cloud security team and the CTO's call to action.
Praise people's effort to adopt your improved security processes. Sympathize with their struggles. Encourage their peers to help. This can be as simple as admitting a component is not working well and capturing that feedback for improvement.
Conversely, sanction negative behaviors that affect the program's adoption. Call out nonconstructive feedback as toxic to the organization and its customers.
This is tough work.
So ensure the right people lead with encouragement, coaching, and accountability.
Sometimes all you need is a respected individual or team to adopt your change and show securing AWS is possible. It's likely their peers will model that same change if they can. Pick your early adopters carefully and help them succeed. Once an early adopter succeeds, promote that trailblazer's success to their peers.
Structural: Change their economy
Integrate security into your organization's economy of measurements and incentives. Security effort should pay off.
Ensure that positive and negative incentives aren’t undermining security. Both generally and in the operation of your critical control loops.
First remove disincentives for integrating security into daily work.
After finding a security issue, be careful not to blame or penalize well-intentioned engineers. These are complex tasks. Show them a better way to complete that task when resolving the issue. Reduce friction for getting help and using tools properly.
Then incentivize sparingly.
Reward teams for doing the right thing and operating safely in their daily work. Don't over-justify security work with special bonuses. Treat security improvements as product improvements and recognize the importance of that work. One way to do this is to create an issue for each team to review their access controls each month. Then publish the total count of completed reviews and improvements in an organization wide newsletter. If you gamified least privilege, publish a leader board. Report security metrics in your organization's 'Ops Reviews' alongside other key metrics.
Hold teams accountable to organization-wide standards for delivering work according to its priority.
Hold security process and component providers accountable. Gather feedback on the process and remove friction. Improve components with weak capabilities or poor usability. This makes the process easier to use over time and shows component providers have skin in the game.
Put it all together
Optimize the access control loop so it produces good results and operates affordably. Set targets for the loop's total execution time and effort for each step. Then find component implementations that enable engineers to hit the targets.
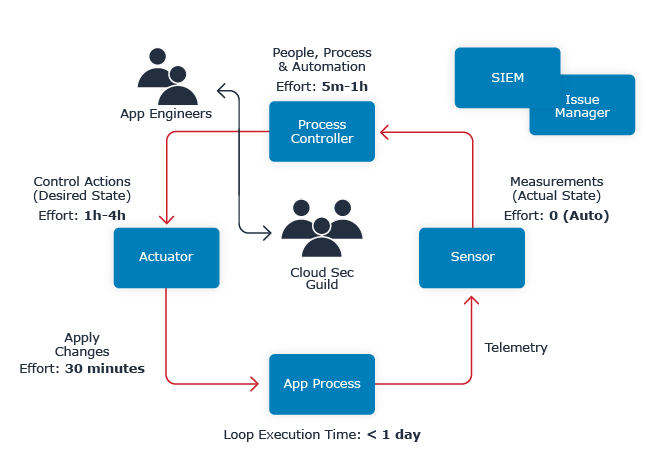
Figure 7.3: Scalable Access Control Loop
Configuring access controls should take less than an hour with usable infrastructure code libraries. Reviewing access for a single application's resources should take 15 minutes or less.
Executing the entire loop should normally take less than one business day. You should be able to deliver a change in a couple hours when there's an incident.
Now you have the information you need to design, implement, and deploy a scalable access control loop in your organization. 🎉
I hope this book has helped you understand the challenges and solutions for building effective access control systems with AWS IAM. You have made a significant and long-lasting investment in your professional development. AWS IAM's features and complexity will grow over time. But AWS is famously committed to backwards compatibility and stability. The concepts and approach described in this book leverage timeless parts of AWS IAM. You can depend on them for many years. Integrate what works for your organization so you can change quickly, confidently, and securely.
Go Fast, Safely.
- Influencer, 2ed, Grenny et al, https://cruciallearning.com/books/#influencer↩